cs231n Training NN part 2
다양한 activation fuction을 반드시 이용해야하는지?

Neural network에서 ac.f 없으면, 개층 구별이 안됨.
ex )

몇개층이든간에 1개로 퉁쳐짐.
쉽게 말해, 사용하면 성능이 좋아짐.
Parameter upadates
확률적 경사 하강법(Stochastic Gradient Descent)은 왜 이렇게 느릴까?

빨간 부분이 sgd 다.
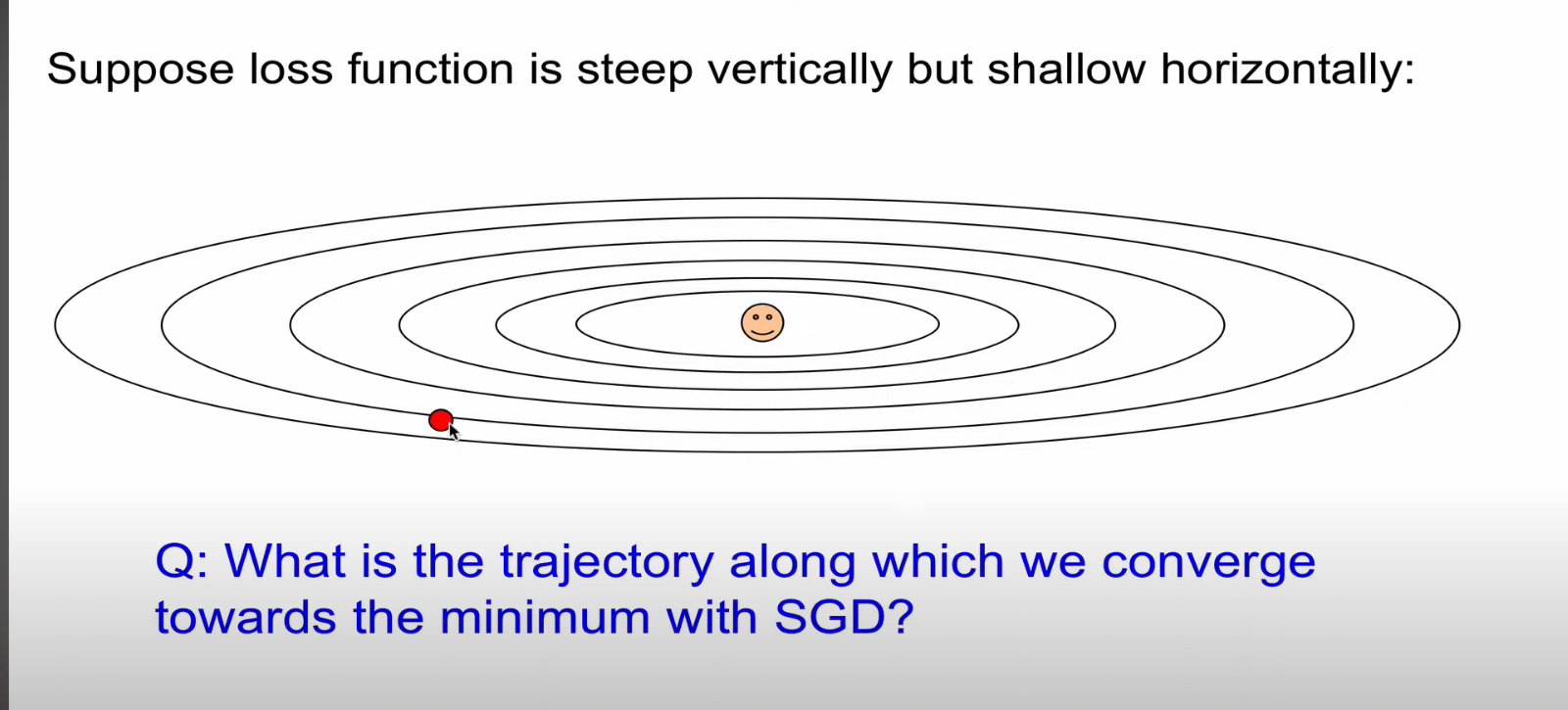
빨간공이 happy point 쪽으로 가야한다.

수직으로는 경사가 높고, 수평으로는 경사가 낮다.

수직으로는 발리이동하고, 수평으로 느리게 이동한다.

지그재그로 매우 느리게 진행한다.
이것을 개선하기위해 모멘텀 업데이트를 한다.

v 는 속도 변수인데, x의 위치를 v를 통해 업데이트 해주는 방식이다.
마치 언덕에서 공을 굴리면, 가속도가 붙는것 처럼 가속도를 계산해주는 방식이다.

경사가 낮은곳에선 속도가 빨라지고, 가파른 곳에서 느리게 올라간다.

초반에는 초록색이 튄다. (overshooting) 그러나 나중엔 더 빠르게 자리를 잡아간다.
다음에 알아볼 것은 네스티로브 모멘텀 업데이트이다.

이것은 NAG (Nestrerov Accelerated Gradeint) 라고도 한다.
이론적으로 momentum rate보다 conversion rate(전환률) 이 항상 좋다고 증명되었 한다.
이유는 다음과 같다.

모멘텀 업데이트의 경우 momentum step과 gradient step의 합으로 actual step을 나타내는 반면,
네스테로브 모멘텀 업데이트의 경우 momentum step을 shfit 한다음 gradient를 구해준다는 원리로 인해, gradient의 방향이 달라진다. (이해x)
식으로 표현하면 네모 부분이 달라진다.
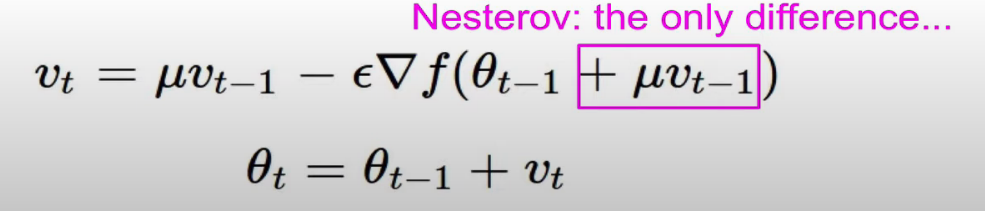
아까 gradident step의 각도가 변한 것처럼, 식부분의 theta값이 바뀌므로 다른 식들과 호환이 안된다는 단점이 있다

Add) 수식 이해는 논문 읽을 때, 필수. 미리 이해하는 연습
퓌 는 그리 중요하지 않으므로 식만 첨부하고 자세히 다루지 않는다.

따라서 이러한 방법으로 속도가 올라간모습을 볼수 있다.

다음 알아볼 것은 아다그라드 업데이트 이다.

catche 라는 개념이 도입되었다.
이 부분까지는 일반적인 스토테스크 그라디언트 인데,

이부분에서 추가로 catche에 루트를 씌워준 것으로 나눠준 것에서 차이가 있다. 여기서 양수이고, catche는 거대한 백터이다.

이런 catche가 빌딩업 되어가면서 parameter들이 업데이트 되는 방식을 아래와 같이 부른다.

아다그란트 업데이트는 왜 사용할까?
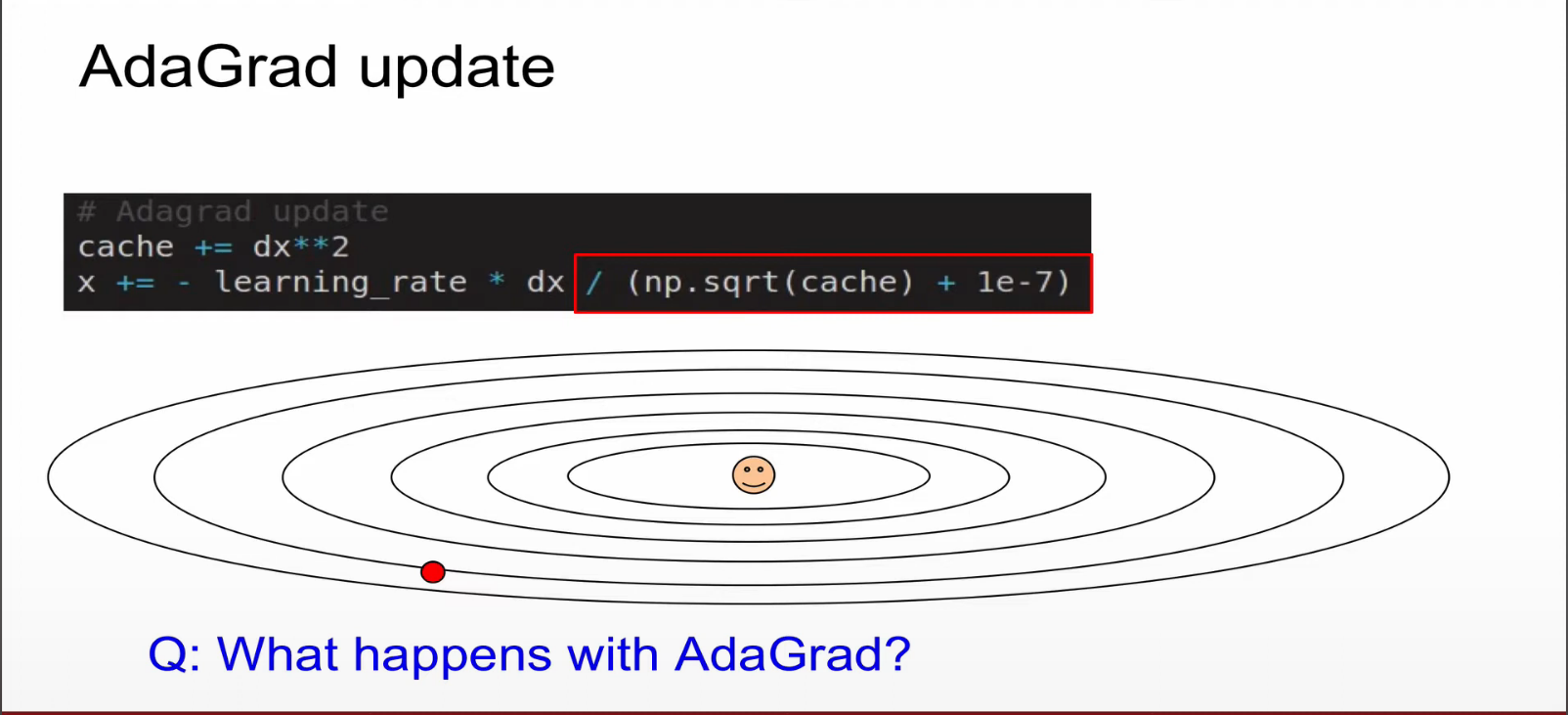
(그림의 원테두리의) 수직축은 그레디언트가 크다는 것은 cache 값이 커진다는 것이고, 분모의 cache값이 커진다는것은 x의 업데이트속도가 낮아진다는뜻이고, 반대로 수평축은 gradient가 작기 때문에 cache가 작고 x의 업데이트가 빠르다.
수직축같은 곳에서는 업데이트 속도를 줄이고, 수평축은 업데이트를 빠르게 해주므로서, 경사에 영향받지 않는 장점이 있다.
아다그란트 업데이트의 문제는 무엇일까?
1) 만약 스텝 사이즈가 시간이 흐름에 따라 증가한다면 어떻게 될까?

cache 값은 계쏙 증가하게 될것이고, learning late는 0에 가까워지고 학습이 종료되는 문제가 있다. (뉴럴넷에서 발생)
이렇게 학습이 종료되는 문제를 개선한 것이 RMSprop 업데이트 이다.

decay_rate 개념을 도입하므로써, cache 값이 서서히 낮아지도록 설정했다.
즉, 경사에 의존하지않는 학습속도의 일관성을 유지 하면서, 스텝사이즈가 0이되었을떄 학습종료되는 문제점을 보완했음.
파란색 검은색 이 다른 방법들보다 빠르게 결과에 도착함.

다음에 볼것이 아담 업데이트
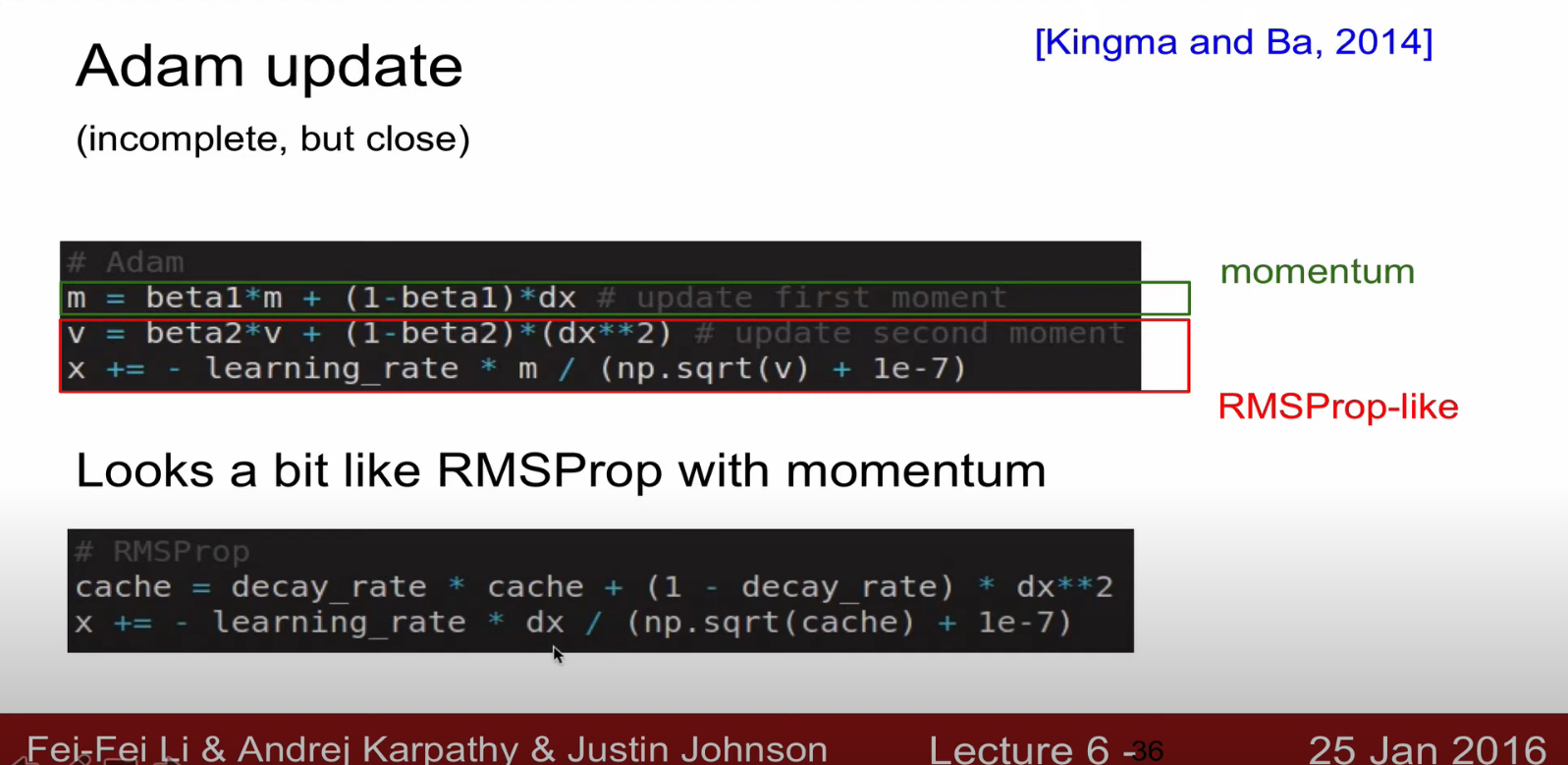
momentum + rms와 비슷한 형태이다.
모두 learning rate를 hyperparmeter로 가진다. 어떤 것을 사용해야할까?

최근 디폴트는 Aam을 가장 많이쓴다.
근데 지금까지 본 모든 방법은 1st order optimization method라고한다. -> 모두 기울기 정보를 사용한 것.
결론: 아담을 쓰고, full batch 사용이 가능하면 그것을 사용하자

앙상블 에대해서 간략히 살펴보자

단일 모델을 사용하지않고, 복수개의 모델을 사용한다.
테스트 타임에 결과의 평균을 내준다.
그럼 간단한 행위로 결과가 2%정도 향상한다.

문제 : 테스트 갯수가 많아지므로, 속도가 느려진다.
재밌는 방법도 소개한다
단일 모델내에서 에포크를 놓을떄마다 체크포인트를 넣고 체크포인트 간에 앙상블을 하더라도 성능 향상이 가능하다.
파라미터 백터간의 앙상들로 성능향상을 가져올 수 있다. why? 지나치는 스텝들을 하나하나 평균을 내면 미니멈에 가까운 것을 얻을 수 있을 것이다.

ADD) 하나의 모델로 개, 고양이 학습. => 모델 5개로 학습. => 모델 5개의 다수결로 정함..
불확실성이 크다 => 정보량이 많다.
drop out (잘이해하는게 중요함)

일반적으로 왼쪽과 같은 방식으로 노드연결이 되는데, 일부 노드들을 랜덤으로 0으로 설정시킴.

누락 된 뉴런은 weight값들이 업데이트가 되지 않음.
이게 도대체 왜 좋은것인지 직관적인 해석방법 소개함.
1. 우리 넷트웤이 몇가지 판단 근거를 고의적으로 없앰. -> 그럼에도 불구하고 정답을 판단할 수 있도록 갖고있는 근거들 내에서 노력하면서 모델이 좋아짐.
ADD) overfitting을 방지하기위함 => 특정 노드만 참고해서 분류하지 않는지 확인

2. 한개의 모델에서 드랍된 랜덤하게 모델을 만들어 내면서, 그것들을 다시 합쳐주면서 앙상블 효과를 줌.

지금까지는 트레닝이였고, 테스트 타임때는 어떻게 할 것이냐. (테스트 타임 : 만들어낸 모델을 통합하는 것)

결론: 테스트 시 드랍아웃을 사용하면 좋지 않음 결과가 나옴.
p가 0.5일때 트레이닝 타임때 우리가 얻을 수 있는 기대
(?)잘모르겠으나, 테스트때 인플레이션된 결과를 얻게돼서, 결과가 별로 안좋다고함.


컨벌루셔널 누럴 네트워크(합성곱 뉴럴 네트워크)

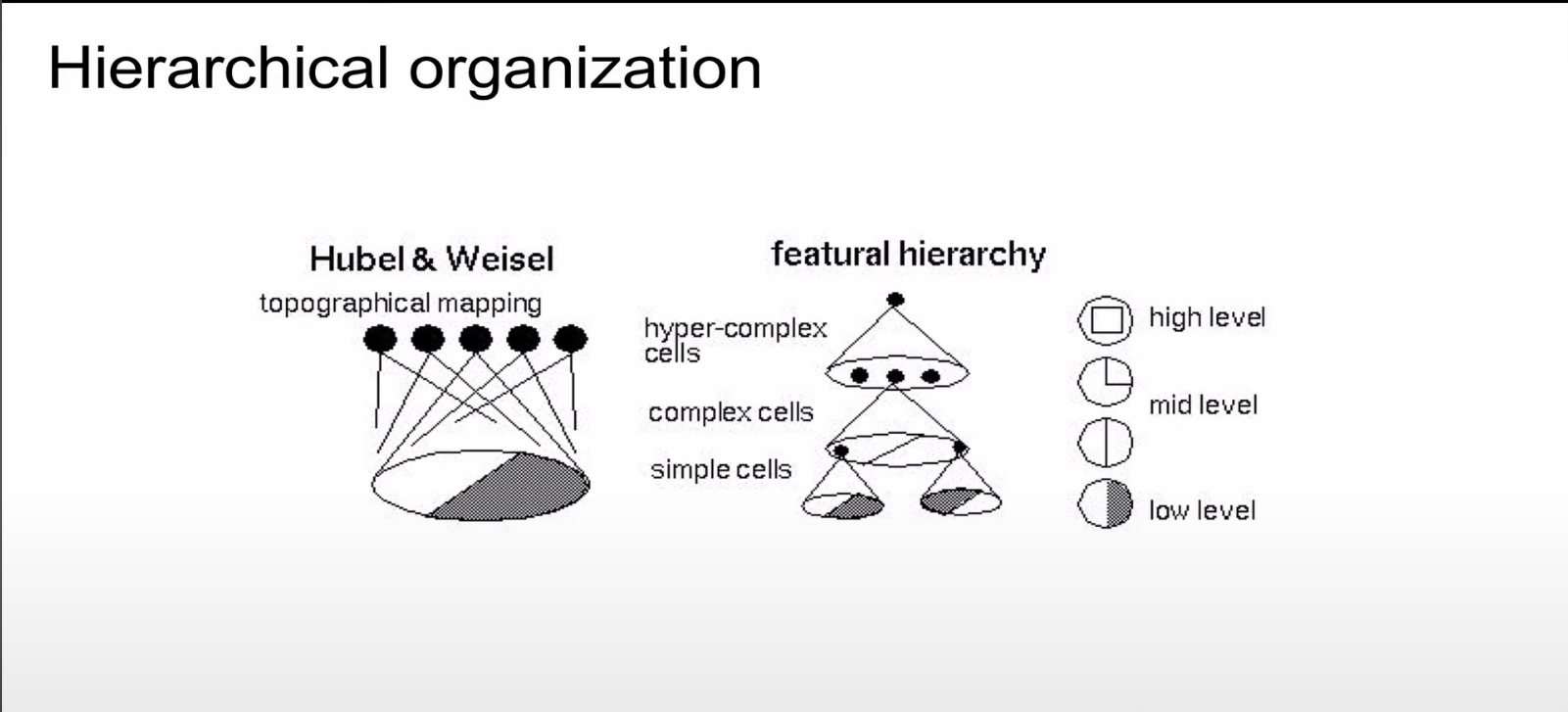
고양이의 시신경으로부터 정보를 받아내는 시신경을 연구함.
특정 뉴런으로부터 전기신호를 받을 수 있게 기계를 연결함.
그 뉴런이 특정 방향에 반응을 하는 뉴런임을 밝혀냄

셀이 실제로 가깝게 있는곳을 실제 시각에서 가깝게 보는 곳을 관장함.

심플셀 부터 하이퍼 컴프렉스셀(전체를 관장하는 셀) 까지 다양한 셀이 있음
뉴로콜그니트론은 작은 셀을 보는 심플 셀과 전체를 관장하는 컴플렉스 셀을 구현한 것임.
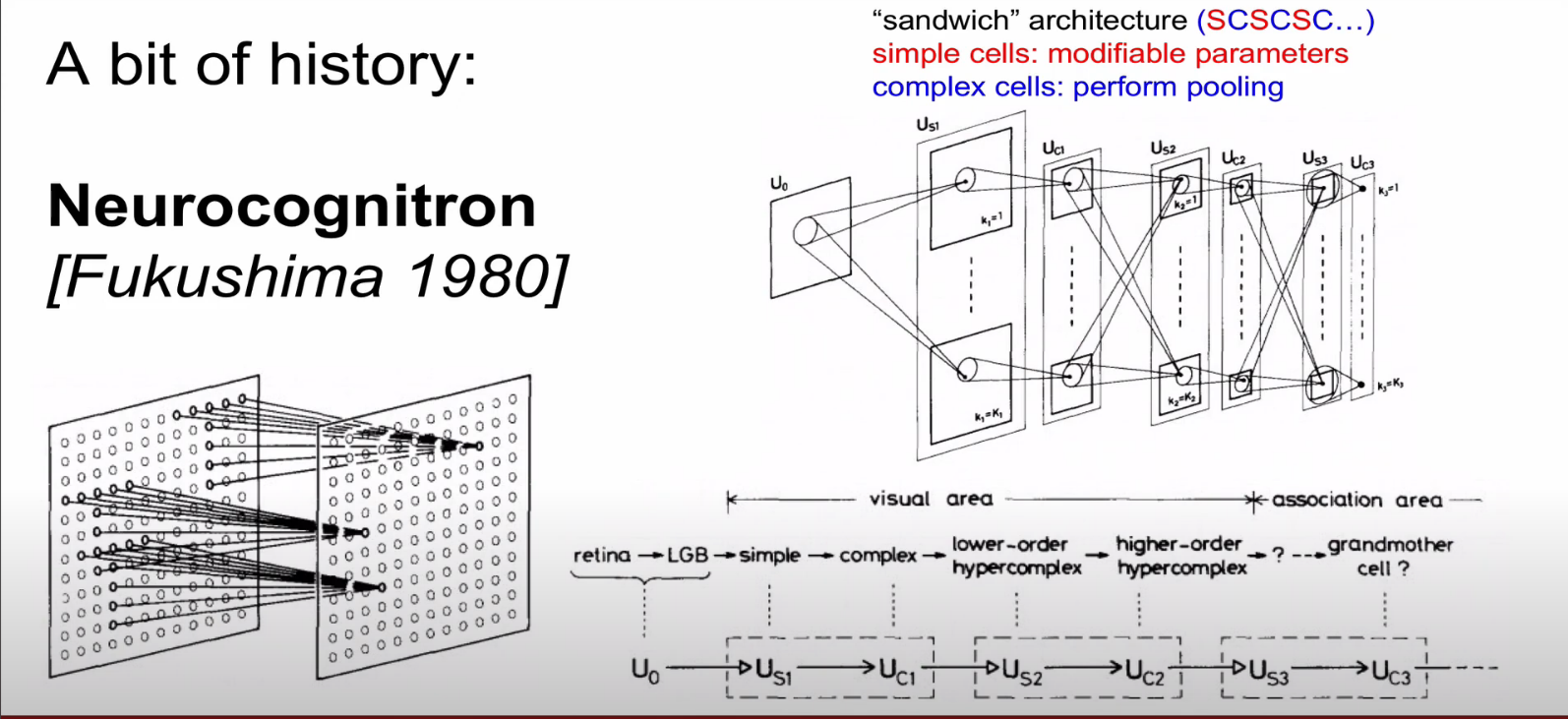
18년이 지나고 실용화된 모습. 우편물의 zip code를 분류하는 기계를 상용하게 만듬.

이후로 비약적인 발전을 하게되고, alex net 이후 확연히 성능이 좋아짐.

재밌는건 앞의 것들과 큰 차이는 없고, gpu의 발전과 weight 초기화 등의 발전 등이 있긴했음. 대부분 다 작은 이유들임.
이후 비슷한 이미지들을 찾아냄. Detection이라고함.

얼굴 인식에도 활용됨.

pose estimation 에도 사용됨.

뉴럴이나, 은하들을 segmentation 함

이미지 생성

원숭이의 하측두 피질의 정확도가 2013년도와 비슷한 수준임.
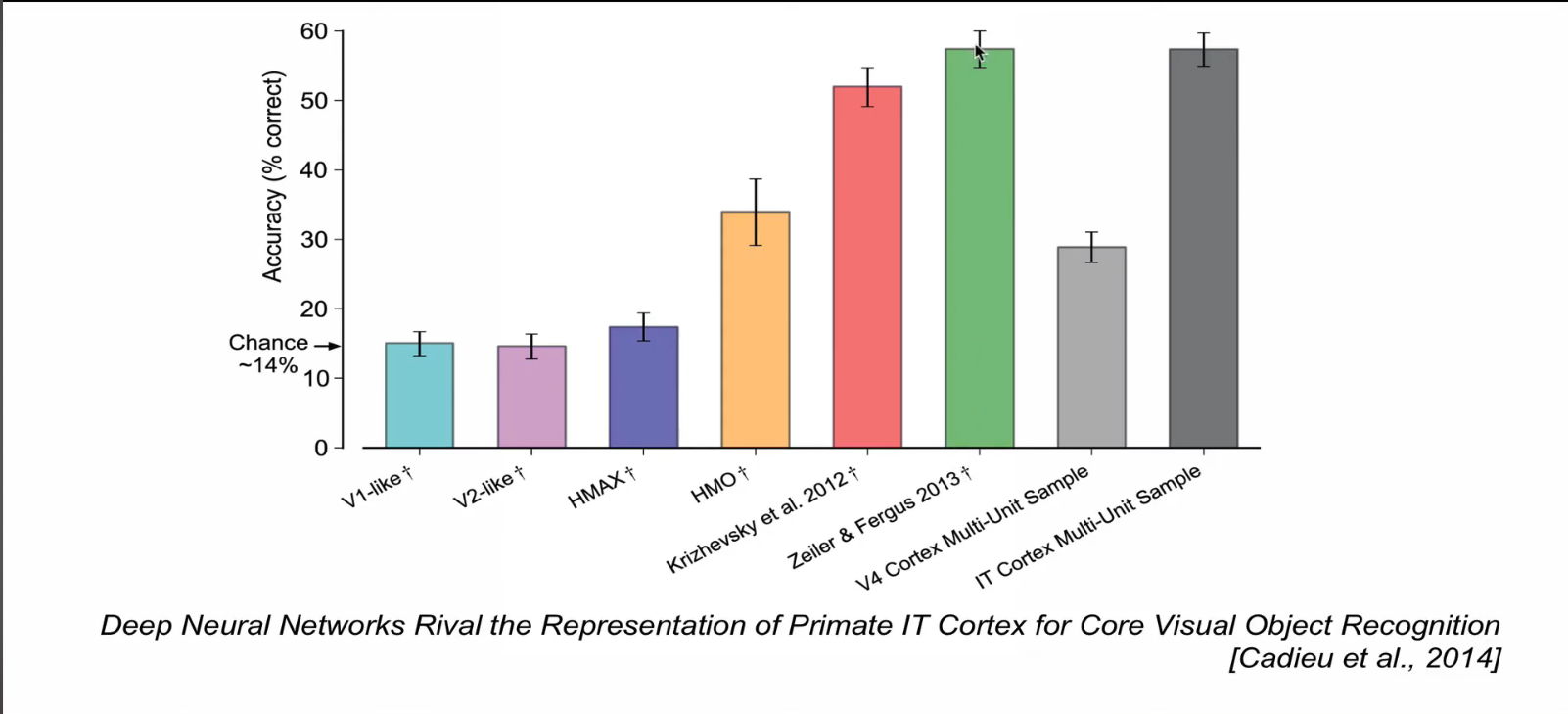
원숭이의 하측두 피질이 측정한 이미지와, 알렉스넷이 측정한 이미지가 매우 유사함. 아마도 사람이상으로, 발전할 가능성이 있음.
