이 포스팅은....
cs231n을 공부하고, 제가 이해한 내용을 정리한 포스팅입니다.
cs231n을 수강하실 목적이 있의거나, AI에 대한 기초 이론 입문용으로 도움이 될 수 있습니다.
Image Classification: 이미지 분류는 Computer Vision의 핵심 기능
컴퓨터 비전을 배우기 위해 먼저 알아야 할 것은 Image는 RGB 총 3개의 array로 구성된 3차원 배열이라는 것입니다.


RGB는 Red, Green, Blue을 뜻하며, 각각의 array가 갖는 element는 [0~255] 사이의 값이 됩니다.
0에 가까울 수록 해당 색상이 어두워지고, 255에 가까울 수록 해당 색상이 밝아지는 방식입니다.
각각의 값을 가진 3개의 RGB값을 더 했을때 나타나야 할 Color Table 값이 존재하며, 이 table을 컴퓨터에 미리 저장해 두었다가 참고하며 색상을 표현합니다.
Image Classification을 위해 해결한 문제 5가지
Challenges : 1. Illumination (이미지의 밝기처리) 2. Deformation (형태가 변형된 이미지 인식) 3. Occlusion (엄폐, 일부 가려짐) 4. Background clutter (배경화면과 구별) 5. Intraclass variation (같은 class 내에서 구별, 종 구별)
과거에 시도했던 Hard coding
하드 코딩으로 이미지를 classification 하는 것은 매우 비효율적인 방법일 뿐 아니라, 성능이 좋지 못했습니다
제프리 힌턴:
과거에도 윤곽과 이미지를 구별하는것은 어떻게든 가능했었다. (저수준으로)
그래서 사과는 이미지 윤곽이 대부분 동그란것에 반해, 성게는 윤곽은 가파른 각이 많이 생기는 현상을 이용해서, 외부 굴곡이 심하게 변하면, 성게, 완만하면 사과로 구별하는 식으로 구별해냈다.
하지만, 성게와 별(5꼭지점을 가진) 같은 것들에는 위의 방식이 슬슬 안통한다.
이것을 해결하기 위해서는 조건이 하나씩 하나씩 점점 더 추가되어야 했고, 나중에 수 많은 복잡성이 생겨 무한대에 가까운 조건을 만들어내야했고 발전하지 못했다.
진보된 방법의 탄생: Data Traning
변경된 방법:
1. 라벨링된 이미지 데이터를 수집합니다.
2. 이미지 분류 방법을 훈련시키기 위해 Machine Learning이 사용합니다.
3. 테스트 이미지를 생성된 이미지 분류 알고리즘에 넣고 평가합니다.
첫번째 분류법: Nearest Neighbor Classifier
- Q)현재 사용하나요? 🤔❓ : 현재 좋은 기술이 많이 나왔기 때문에 사용하지않습니다. 단, 교육용으로 적합합니다.
- 요약) 📝 모든 학습용 이미지, 레이블을 기억 -> 예측 단계에서 모든 트레이닝 이미지와 테스트 이미지 비교.
- CIFAR - 10) 📸🔟 60,000개의 32 X 32 컬러 이미지를 10개 클래스로 분류하여, 50,000개의 훈련 이미지, 10,000개의 테스트 이미지를 제공.
- 테스트시 정확하지 않음 (결과가 이상함) 🤔why❓ 단순 distance matricx로 비교하기 떄문.
- What is the Distance Metric : 📏🔢

- 분류 속도는 데이터 사이즈에 따라 Linearly하게 늘어납니다. 🤔❓ 모든 데이터와 비교하면서 distance를 측정해야 하기 때문에.
이런점이 이미지 훈련 시간은 작지만, 이미지 test 처리수행 시간이 길어서, 바로바로 결과값이 나와야하는 CV 산업에서 단점으로 작용한다.
- Manhattan Vs Euclidean



-KNN


Euclidean
- Manhattan?
- Training data 중 하나를 (NN)nearest neighbor classifier 방식에 의해 분류를 하게 되면, 정확도를 측정하면?
Training 데이터 안에 자기 자신을 만나게 되므로, 100퍼센트 정확도를 보일 것이다. (유클리 맨하튼 같다)
- 반면 동일한 조건으로 KNN으로 분류하게 되면?
K = 5 일경우 1위는 정확도 100퍼센트로 예측하게 되지만, 2,3,4,5위에 엉뚱한 분류가 진행될 경우 다수결에 의해 결과값이 바뀔 수 있다.
- KNN ( 가장 가까운 K개의 데이터를 찾고, 다수결로 결정 )
- L1, L2 중 무엇을 사용할것인가? , 무엇이 최적의 K 값인가? (이러한 것들을 hyperparameter 라고 한다.)
문제에 따라 다르게된다. 각각의 환경에서 실험후 퍼포먼스가 가장 잘나오는 것 실험.
- test set은 절대 사용하면 안된다. (성능 평가를 위해서)

- 그럼 어떻게 hyperparameter를 조정하기위한 test를 하는가?

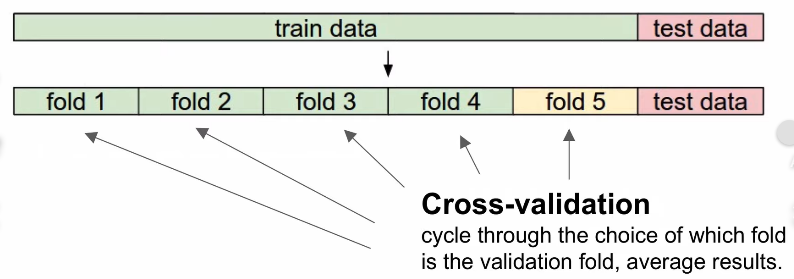
- k를 5개로 했을때, 각 k 1 ~ 5의 값들의 평균을 보고, 가장 점수가 높은 것을 선택함.

- knn 은 현실에서 사용하지 않음.

L2 distance가 모두 같다는 의미가 이해가 잘안감.
< Neural Networks practitioner >
- CNN(이미지 classification에 강함), RNN(문자 목소리 동영상 등 Sequence 처리에 강함)
-앞으로 배울것 - Parameter 기반의 approach

Parameters을 조절하여 3072개 (32 X 32 X 3)의 값을 입력하였을때, 10개의 숫자로 출력해줌.

이미지 array인 32 X 32 X 3을 쭉 펴서 한개의 긴~ 행렬을 만듬. ->
x의 행렬 (3072 X 1) : A
W의 행렬 (10 X 3072) : B
Wx = BA = (10 x 3072) x (3072 x 1) = (10 x 1)


- Linear Classifier 을 한문장으로 표현한다면?
이미지내의 모든 곱셈 값들에 대해서 가중치를 곱해서 처리를 한 값이다. = jsut a weighted sum of all the pixel values in the image
각각 다른 공간적 위치에 있는 color들을 counting 한 것이다. = counting colors at different spatial position
- Linear classifier 의 가중치를 이미지화 한 이미지
